
Meaningful Word Count For Your Markdown
I love Markdown. I use it to write documentation, articles, and even email. But one issue when writing in Markdown is trying to get a meaningful word count as your draft comes along. While the go-to word count solutions I've tried (and maybe you've tried) do provide word counts, they're inaccurate due to the markup present in Markdown. In this article, I'll share with you a solution that provides a meaningful word count where others fall short.

Go-to Solution #1: wc
The Unix command wc, by default, provides line1, word, and byte counts
for given input. For example:
$ echo 'This is nine words,
fifty-nine characters, and
three lines' | wc
3 9 59
And to just output the word count:
$ echo 'This is nine words,
fifty-nine characters, and
three lines' | wc -w
9
Note that according to the man page for wc:
A word is defined as a string of characters delimited by white space characters.
Now consider this minimal Markdown document intended to be a post in your Jekyll blog:
---
title: "Shouldn't Be Counted"
tags:
- shouldn't-be-counted
- shouldn't-be-counted-either
---
## Word Count
This document has a **lot** of [words]("https://example.com") (15).[^1]
code is counted
[^1]: Footnotes count.
Here's what wc counts:
$ echo '
---
title: "Shouldnt Be Counted"
tags:
- shouldnt-be-counted
- shouldnt-be-counted-either
---
## Word Count
This document has a **lot** of [words]("https://example.com") (15).[^1]
code is counted
[^1]: Footnotes count.
' | wc -w
28
28 words. wc is counting all of what it defines as words, including the
front matter (the metadata within the leading --- area) and all symbols
throughout. Only half of those "words" are shown to the reader.
Go-to Solution #2: "Word Count" extension for Visual Studio Code
I'm a big fan of Visual Studio Code and I use it a lot in my day-to-day development. The editor also happens to support Markdown with syntax highlighting and a rendered preview window. That, combined with Code's integrated terminal, is all I need to locally develop my blog.
So I searched for a word count extension for Markdown and downloaded the most popular one—"Word Count"—which has over 30k downloads and is also developed by Microsoft.
Unfortunately, it seems to to count words in the same way that wc does:
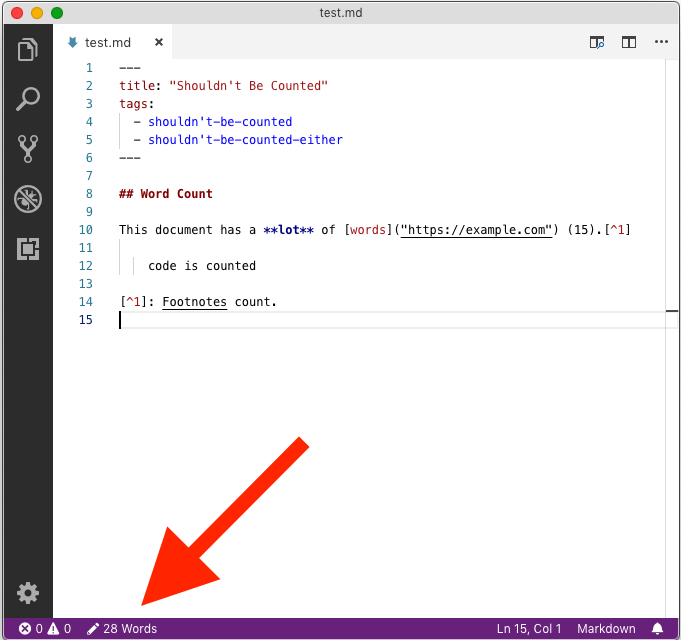
28 words.
Pandoc: A More Meaningful Word Count
Pandoc is a powerful "universal document converter" that is the engine to many document conversion solutions, like the one that converts this site from Markdown to HTML. Within Pandoc is a feature called filters which operates between the input and output of the conversion. Though there's a ton you can do with filters, I'll just be showing you how to implement one that will provide a word count minus front matter and Markdown symbols.
Install Pandoc
There are many ways to install Pandoc, so pick your poison. Here's how I installed with Homebrew on macOS:
$ brew install pandoc
Create Configuration Folders
Before we can add custom filters for Pandoc to use, we have to create some folders in Pandoc's "path", so to speak.
First, we'll need to see where the "default user data directory" is:
$ pandoc --version
pandoc 2.7.3
Compiled with pandoc-types 1.17.5.4, texmath 0.11.2.2, skylighting 0.8.1
Default user data directory: ~/.local/share/pandoc or ~/.pandoc
Copyright (C) 2006-2019 John MacFarlane
Web: http://pandoc.org
This is free software; see the source for copying conditions.
There is no warranty, not even for merchantability or fitness
for a particular purpose.
Next, we need to create two folders in the first listed directory from above:
$ mkdir -p ~/.local/share/pandoc/filters
The -p option for mkdir creates both folders at once.
Create and Save Custom Filter
The maintainers of Pandoc are kind enough to provide a filter that does exactly what we're after—produce a word count minus front matter and Markdown symbols. You can find it here, along with other filters. Here's the exact script below:
-- counts words in a document
words = 0
wordcount = {
Str = function(el)
-- we don't count a word if it's entirely punctuation:
if el.text:match("%P") then
words = words + 1
end
end,
Code = function(el)
_,n = el.text:gsub("%S+","")
words = words + n
end,
CodeBlock = function(el)
_,n = el.text:gsub("%S+","")
words = words + n
end
}
function Pandoc(el)
-- skip metadata, just count body:
pandoc.walk_block(pandoc.Div(el.blocks), wordcount)
print(words .. " words in body")
os.exit(0)
end
Save the above into a file named wordcount.lua in the newly created folder
from above e.g. ~/.local/share/pandoc/filters/wordcount.lua
Use It
Pandoc can read from standard input (stdin) or a file. You'll need to invoke
pandoc with an option that will apply our custom filter and output it's
result. If you read from a file, don't worry—the original file won't be altered.
To use our simple example from above:
$ echo '
---
title: "Shouldnt Be Counted"
tags:
- shouldnt-be-counted
- shouldnt-be-counted-either
---
## Word Count
This document has a **lot** of [words]("https://example.com") (15).[^1]
code is counted
[^1]: Footnotes count.
' | pandoc --lua-filter wordcount.lua
15 words in body
15 words.
Bonus: Create a shortcut to invoke this filter
pandoc --lua-filter wordcount.lua is a handful to type. We can create a shell
function to simplify this.
Add and save the below to your ~/.bash_profile:
wordcount() {
pandoc --lua-filter wordcount.lua "$@"
}
Now if you quit your shell and reopen it, we can invoke our custom filter like this:
$ echo '# This should be five words' | wordcount
5 words in body
Voilà! A word count that counts words that a reader reads and not all the markup in Markdown.
What's your favorite command line solution lately?
-
Note that only lines ending with the new line character (
\n) are counted as lines. This can lead to unexpected results, which is why I useawkfor line counts with this one-liner:awk 'END { print NR }'↩︎
Leave a comment